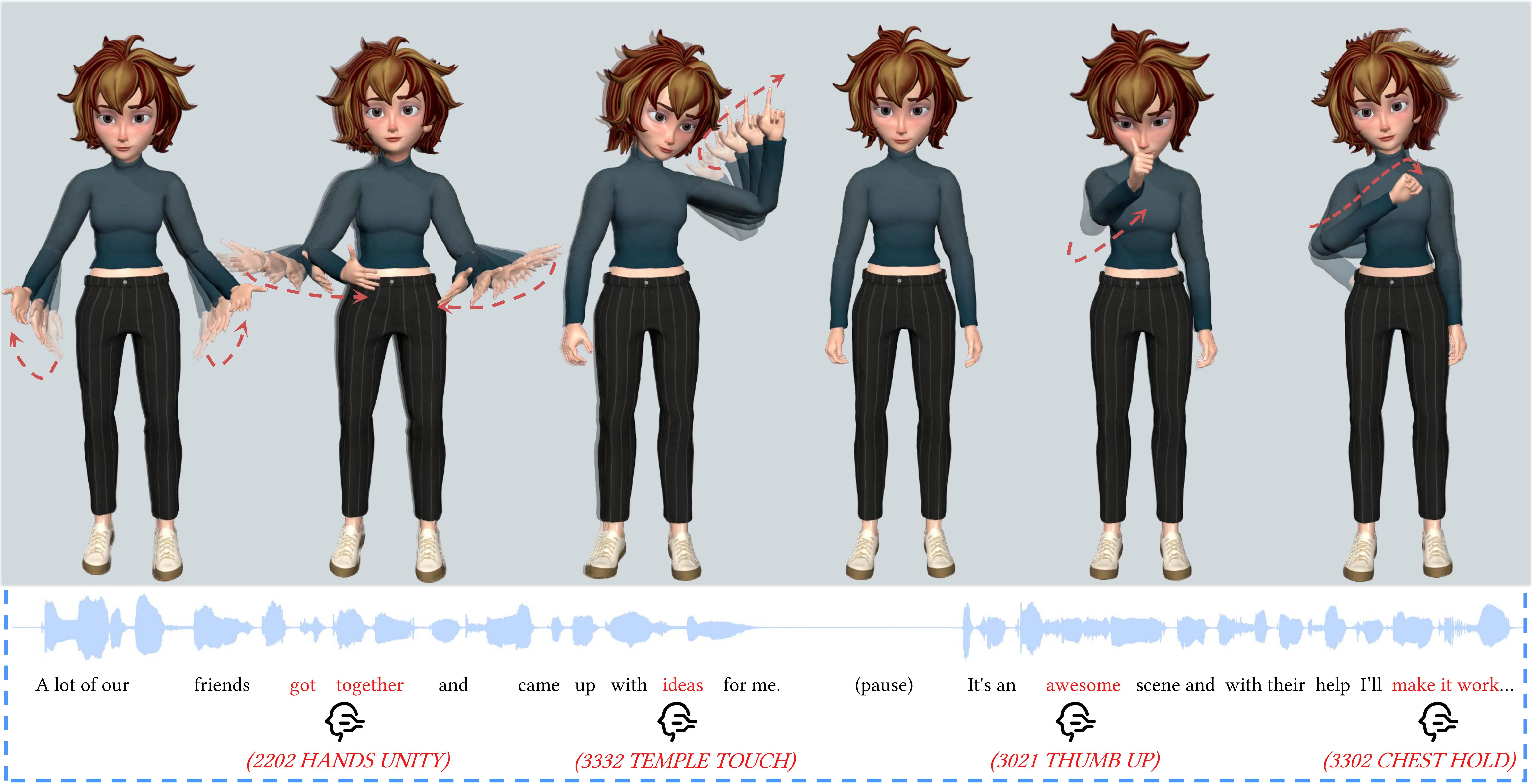
In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
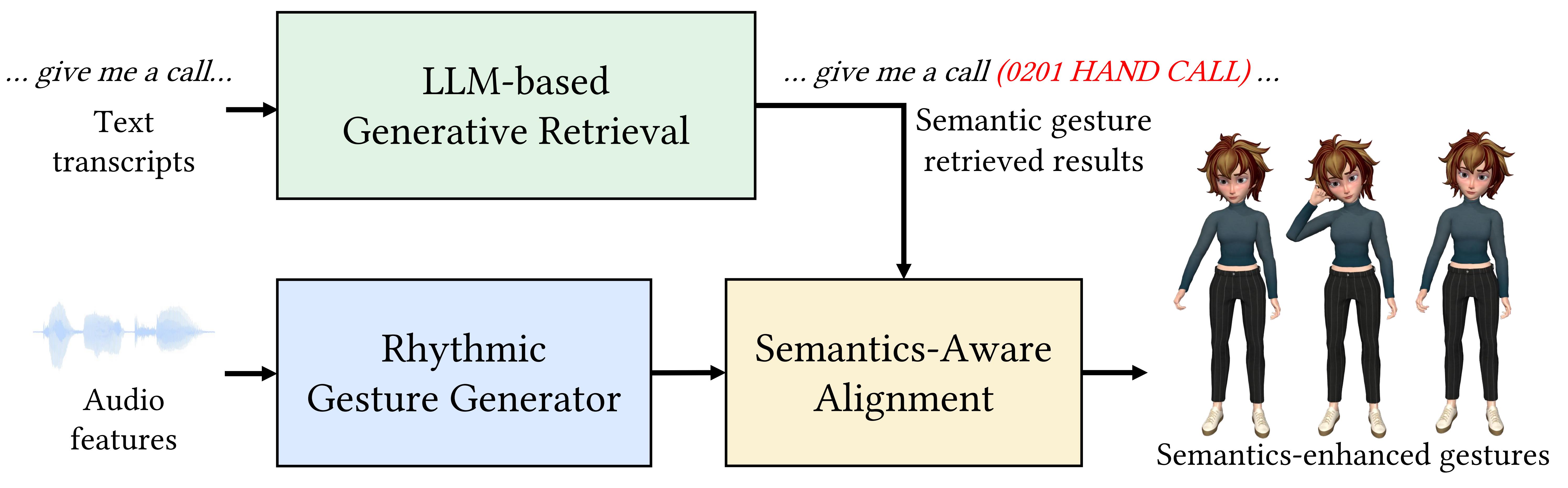
Our system processes audio and speech transcripts as inputs to generate realistic full-body gestures, including finger motion, that are both rhythmically and semantically aligned with the speech content. It is capable of robustly synthesizing sparse semantic gestures, vital for effective communication. It is built upon a discrete latent motion space, learned through the use of a residual VQ-VAE. This approach tokenize a sequence of gestures into hierarchical and compact motion tokens, ensuring both motion quality and diversity. As illustrated above, our system comprises three key modules: (a) an end-to-end neural generator capable of processing a diverse range of speech audio inputs to produce rhythm-matched gesture animations utilizing the GPT architecture; (b) a large language model (LLM)-based generative retrieval framework that comprehends the context of the transcript input and retrieves appropriate semantic gestures from a high-quality motion library covering commonly used semantic gestures; and (c) a semantics-aware alignment mechanism that integrates the retrieved semantic gestures with the rhythmic motion generated, resulting in semantically-enhanced gesture animation. In subsequent sections, we detail the components of our system and their respective training processes.
Semantic Gesticulator surpasses all baseline comparisons in terms of both qualitative and quantitative measures, demonstrated by the results of FGD and SC metrics, as well as user study outcomes. For applications, we devise an augmentation framework for identifying semantically similar gestures from an extensive collection of 2D videos, thereby enhancing the diversity of gestures. Moreover, through customizing a 2D video library, users can flexibly edit the style of final outcomes.
Our system successfully creates realistic gestures that accurately convey the intended meanings, aligning with the respective retrieval results. The character performs a range of semantic gestures, including natural body movements, reasonable arm swings, and delicate finger gesticulations. Here are some results:
We compile a comprehensive set of semantic gestures commonly used in human communication, drawing on relevant linguistic and human behavioral studies. Based on this collection, we record a high-quality dataset of body, hand, and finger movement using motion capture. This dataset contains over 200 types of semantic gestures, each offering a variety of gestures. Some examples are shown below.
0310 FINGERS BECKON
3031 ARMS WELCOME
0220 FINGERTIPS KISS
3030 HAND OPEN
2113 PALMS FRONT
3021 THUBM UP
We devise an augmentation framework for identifying semantically similar gestures from an extensive collection of 2D videos, thereby enhancing the diversity of gestures. Moreover, through customizing a 2D video library, users can flexibly edit the style of final outcomes.
@article{zhang2024semantic,
title={Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis},
author={Zhang, Zeyi and Ao, Tenglong and Zhang, Yuyao and Gao, Qingzhe and Lin, Chuan and Chen, Baoquan and Liu, Libin},
journal={ACM Transactions on Graphics (TOG)},
volume={43},
number={4},
pages={1--17},
year={2024},
publisher={ACM New York, NY, USA}
}