The automatic generation of stylized co-speech gestures has recently received increasing attention. Previous systems typically allow style control via predefined text labels or example motion clips, which are often not flexible enough to convey user intent accurately. In this work, we present GestureDiffuCLIP, a neural network framework for synthesizing realistic, stylized co-speech gestures with flexible style control. We leverage the power of the large-scale Contrastive-Language-Image-Pre-training (CLIP) model and present a novel CLIP-guided mechanism that extracts efficient style representations from multiple input modalities, such as a piece of text, an example motion clip, or a video. Our system learns a latent diffusion model to generate high-quality gestures and infuses the CLIP representations of style into the generator via an adaptive instance normalization (AdaIN) layer. We further devise a gesture-transcript alignment mechanism that ensures a semantically correct gesture generation based on contrastive learning. Our system can also be extended to allow fine-grained style control of individual body parts. We demonstrate an extensive set of examples showing the flexibility and generalizability of our model to a variety of style descriptions. In a user study, we show that our system outperforms the state-of-the-art approaches regarding human likeness, appropriateness, and style correctness.
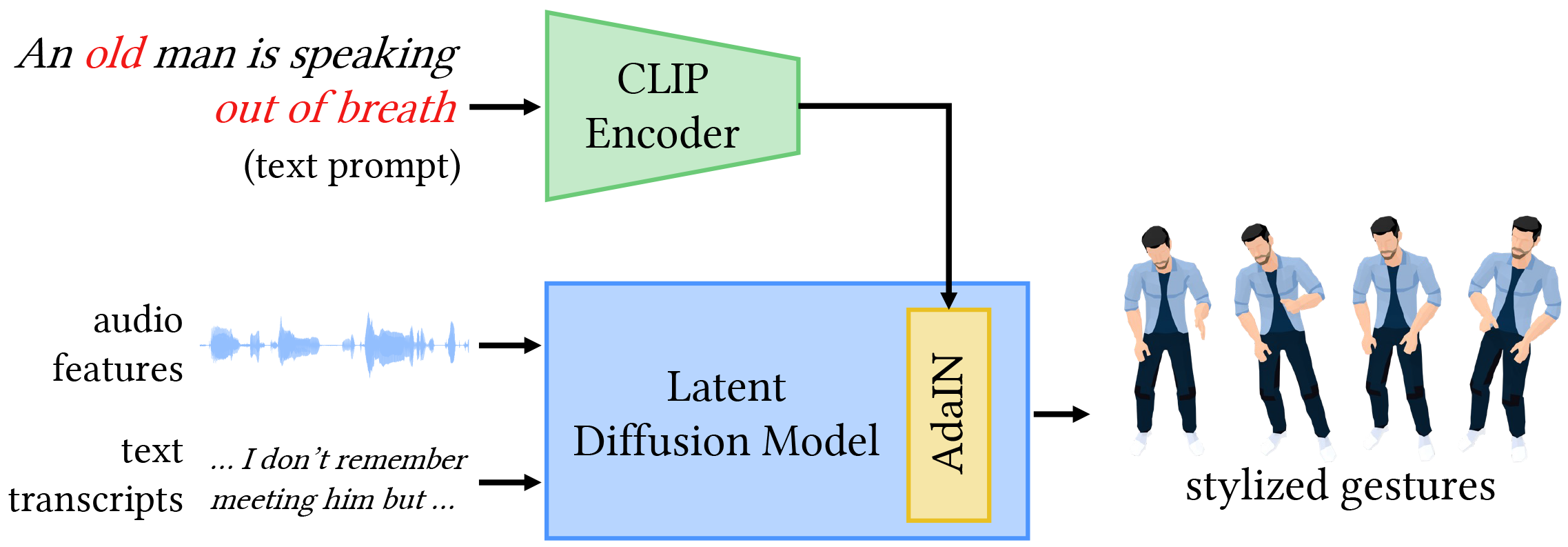
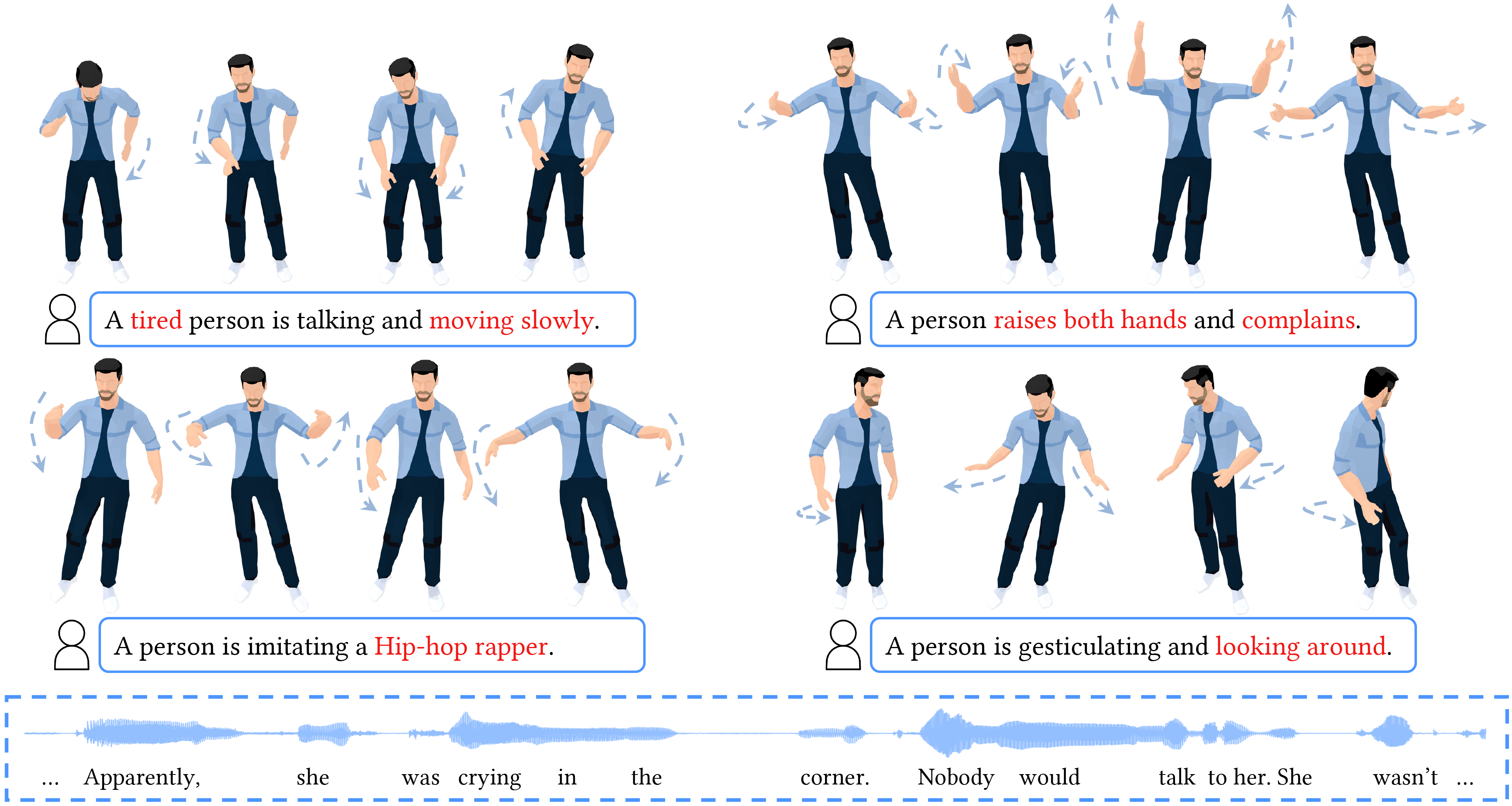
GestureDiffuCLIP takes the audio and transcript of a speech as input, synthesizing realistic, stylized full-body gestures that align with the speech content rhythmically and semantically. It allows using a short piece of text, namely a text prompt, a video clip, namely a video prompt, or a motion sequence, namely a motion prompt, to describe a desired style. The gestures are then generated to embody the style as much as possible. And furthermore, our system can be extended to achieve style control of individual body parts through noise combination.
We conduct an extensive set of experiments to evaluate our framework. Our system outperforms all baselines both qualitatively and quantitatively, as evidenced by FGD, SRGR, SC, and SRA metrics, and user study results.
Our system accepts text, motion, and video prompts as style descriptors and successfully generates realistic gestures with reasonable styles, as required by the corresponding prompts. Some of the results are as follows.
Text Prompt: “the person is angry.”
Text Prompt: “the person is happy and excited.”
Text Prompt: “the person is sad.”
Text Prompt: “a person is holding a cup of coffee in the right hand.”
Text Prompt: “the person is playing the guitar.”
Text Prompt: “standing like a boxer.”
(The left video is the video prompt, and the right video shows the results.)
Video Prompt: “a dance of hip-hop style.”
Video Prompt: “a yoga gesture.”
Video Prompt: “a yoga gesture.”
Video Prompt: “a bird flaps wings in flight.”
Video Prompt: “trees sway with the wind.”
Video Prompt: “flames burn in the fireplace.”
Video Prompt: “a standing dinosaur.”
Video Prompt: “lightning descends from the sky.”
(The left video is the motion prompt, and the right video shows the results.)
Motion Prompt: “high right hand and low left hand.”
Motion Prompt: “sitting.”
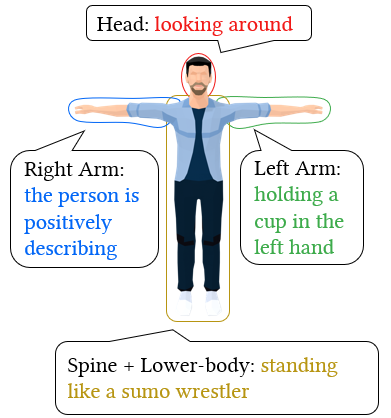
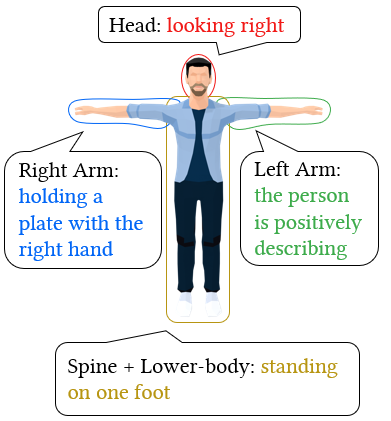
Our system allows fine-grained styles control on individual body parts by using noise combination. We employ different prompts to control the styles of various body parts. The resulting motions produce these styles while maintaining a natural coordination among the body parts.
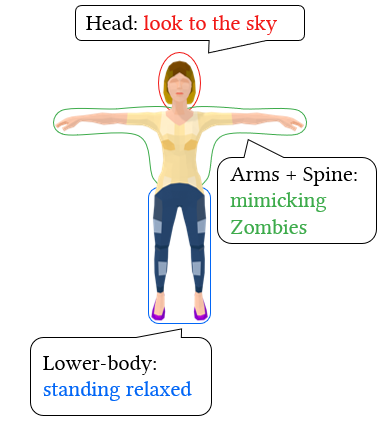
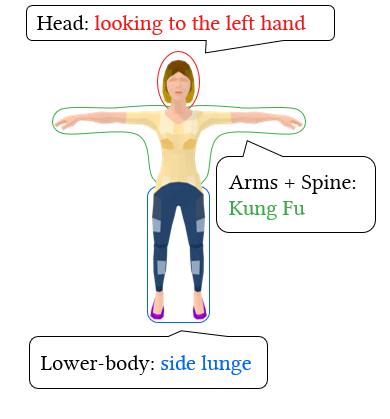
We demonstrate that our system can effectively enhance co-speech gestures by specifying style prompts for each speech sentence and using these prompts to guide the character's performance. We can further automate this process by employing a large language model like ChatGPT, enabling a skillful storyteller.
(The highlighted yellow text is the guidance added by LLM for actions.)
@article{
Ao2023GestureDiffuCLIP,
author = {Ao, Tenglong and Zhang, Zeyi and Liu, Libin},
title = {GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents},
journal = {ACM Trans. Graph.},
issue_date = {August 2023},
numpages = {18},
doi = {10.1145/3592097},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {co-speech gesture synthesis, multi-modality, style editing, diffusion models, CLIP}
}